TechnoLynx
Seeking solutions beyond limits? Our expertise in AI, GPU programming and optimisation is your gateway to success.
Explore how we can transform your business.
Who We Are
Hunting For
Optimum
TechnoLynx is a Software Research and Development Consulting Company. We help high-tech startups and SMEs advance their core technology, business and IP. TechnoLynx offers a strategic path to maximising your return on investment through tailored solutions.
What We Do
We specialise in guiding clients through the entire research and development journey, from initial prototyping to seamless integration and even safeguarding intellectual property. As an innovative solutions center, we not only identify areas for workflow enhancement but also actively engage in crafting and implementing solutions.
R&D Success =
Realistic Expectations +
Quality Execution
A staggering 80% of real-world AI projects fail due to not meeting heightened expectations and ignoring operational, organisational, and regulatory challenges.
TechnoLynx is happy to help even AI-first-timer clients explore the most relevant part of state-of-the-art to supercharging their business. We aim to agree on a realistic scope and ruthlessly deliver the most out of it.
Grants
Looking for help from funding to revenue? TechnoLynx can join you for your R&D&I grant applications like Horizon Europe and more. Explore ways on how can we mutually help each other.
Technical Excellence
Founded in 2019 by Balázs Keszthelyi, co-inventor of more than a dozen patents and contributor to two international standards, we know how to beat the state-of-the-art.
Balázs’ passion for high quality and superior performance sets a high bar, generating value for our clients and growth for our employees.
Responsible All the Way
Consultancies focusing on theoretical best practices but not implementations and software houses concentrating on the best delivery of the technical scope may both do an excellent job. Still, the result may land in the drawer.
TechnoLynx ventures out in the business woods just enough to understand the business problem and hunt down the best solutions. We expand our responsibility to make sure we are solving the right problems, otherwise, we stick to what we know best: inventing technologies and making software.
Also in software and
looking for a referral partner?
What Happens for the Client,
Stays with the Client
Outsourcing core technology development may be seen as a risky venture because the contractor may ultimately get leverage over the client for knowing the IP best.
At TechnoLynx, we have the tightest IP clauses applied both with our clients and our own employees, making sure that anything generated within the remit of a project is owned by the client.
Articles


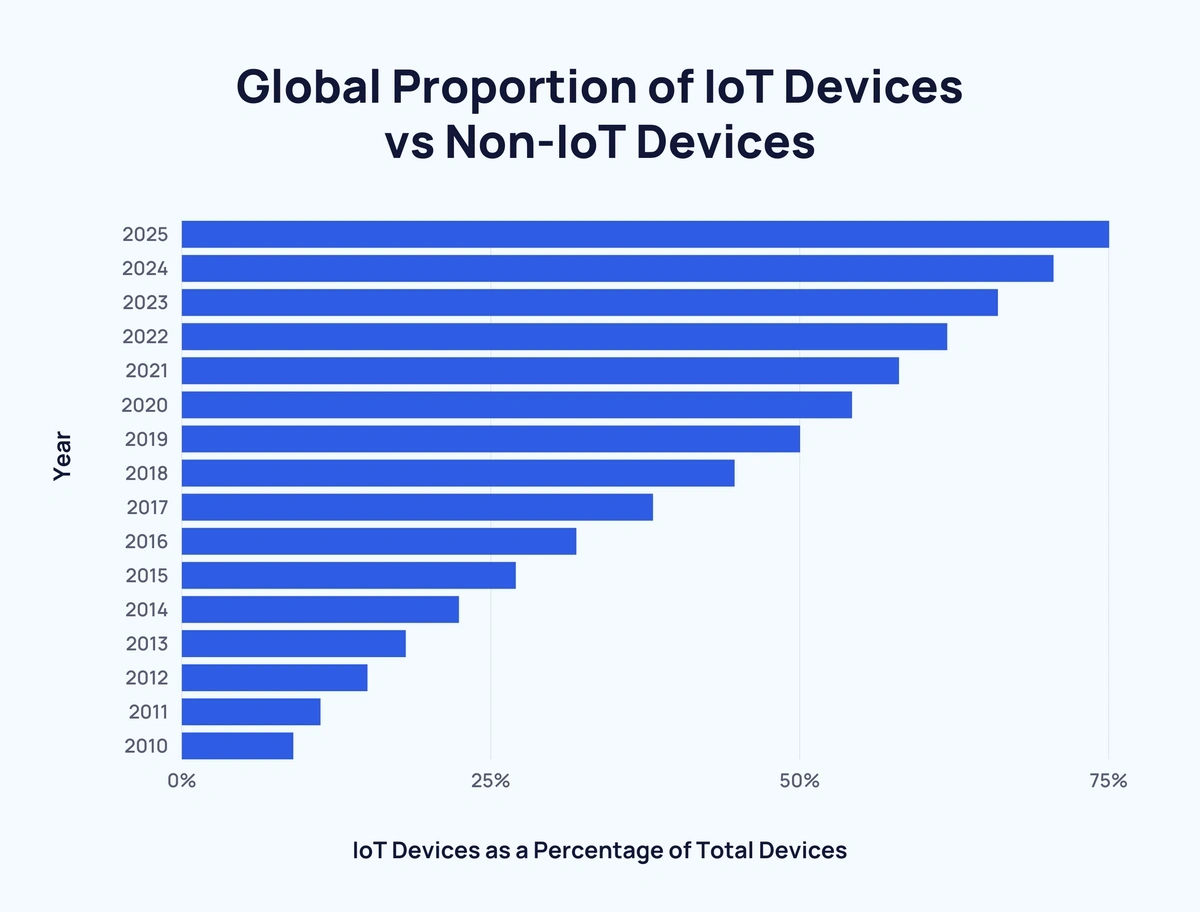








Incremental Value
No Leap of Faith
Moonshot digital transformation often leaves stakeholders disillusioned. The lack of early results may be interpreted as a stalling project in their eyes, leading to cancellation.
TechnoLynx prioritises stakeholder involvement via incremental updates and works toward establishing an agile delivery cadence. We prefer going with the tried and tested first before moving on to shiny new things.